


Spark pour la data science
Prochaine session
1er et 2 juin 2026
Prochaines sessions et informations pratiques
- Comprendre l’architecture de Spark et ses concepts fondamentaux.
- Manipuler des données efficacement avec les API structurées (DataFrames, SQL).
- Réaliser des transformations avancées et gérer des jointures complexes.
- Explorer des cas d’utilisation avancés tels que le streaming structuré et l’apprentissage automatique (MLlib).
- Améliorer les performances des pipelines de traitement des données.
- Comprendre l’architecture de Spark et ses concepts fondamentaux.
- Manipuler des données efficacement avec les API structurées (DataFrames, SQL).
- Réaliser des transformations avancées et gérer des jointures complexes.
- Explorer des cas d’utilisation avancés tels que le streaming structuré et l’apprentissage automatique (MLlib).
- Améliorer les performances des pipelines de traitement des données.
Connaissances de base en programmation Python et en manipulation de données.
Connaissances de base en programmation Python et en manipulation de données.
Cette formation s’adresse à tous les professionnels débutant sur Spark souhaitant se familiariser avec le traitement de données massives. Elle est particulièrement adaptée aux ingénieurs data, data scientists et data analysts.
Cette formation s’adresse à tous les professionnels débutant sur Spark souhaitant se familiariser avec le traitement de données massives. Elle est particulièrement adaptée aux ingénieurs data, data scientists et data analysts.
Découvrir les bases de Spark
- Introduction : vision et architecture de Spark
- Prise en main : configuration de Spark, démarrage de SparkSession
- Manipulation de données : création et transformation de DataFrames, utilisation de SQL
- Travail avec les formats de données : JSON, CSV, Parquet
- Concepts clés : partitionnement, transformations paresseuses et actions
Approfondir et pratiquer
- Joins et agrégations avancées : techniques et optimisation
- Streaming structuré : introduction au traitement des flux de données en temps réel
- Machine learning avec MLlib : mise en œuvre de modèles de régression, classification et recommandation
- Optimisation : techniques de tuning, variables de diffusion et partitionnement
- Études de cas pratiques
Découvrir les bases de Spark
- Introduction : vision et architecture de Spark
- Prise en main : configuration de Spark, démarrage de SparkSession
- Manipulation de données : création et transformation de DataFrames, utilisation de SQL
- Travail avec les formats de données : JSON, CSV, Parquet
- Concepts clés : partitionnement, transformations paresseuses et actions
Approfondir et pratiquer
- Joins et agrégations avancées : techniques et optimisation
- Streaming structuré : introduction au traitement des flux de données en temps réel
- Machine learning avec MLlib : mise en œuvre de modèles de régression, classification et recommandation
- Optimisation : techniques de tuning, variables de diffusion et partitionnement
- Études de cas pratiques
Spark pour la data science ? Une bonne idée !
Spark est un système de traitement de données open source et distribué, conçu pour fournir une plateforme de calcul rapide et évolutive. Il a été initialement développé à l’Université de Californie à Berkeley et est maintenant maintenu par la fondation Apache. Tout comme Python, Spark est un excellent choix pour faire de la data science :
Vitesse de traitement élevée : Spark est conçu pour le traitement de données en mémoire, ce qui lui permet d’atteindre des performances élevées. Il effectue des opérations de transformation et d’analyse des données de manière très rapide, ce qui permet de réduire considérablement les temps de calcul par rapport à d’autres systèmes.
Capacité de traitement distribué : Spark utilise un modèle de traitement distribué, ce qui signifie qu’il peut répartir les tâches sur plusieurs nœuds d’un cluster. Cela permet de traiter de grands ensembles de données en parallèle, ce qui améliore les performances et permet de faire face à des charges de travail importantes.
Support de plusieurs langages : Spark offre des API dans plusieurs langages de programmation, notamment Scala, Python, Java et R. Cela permet aux utilisateurs de choisir le langage avec lequel ils sont le plus à l’aise et facilite l’intégration de Spark dans leurs workflows existants.
Richesse des fonctionnalités : Spark offre une large gamme de fonctionnalités pour le traitement et l’analyse des données. Il prend en charge le traitement de flux de données en temps réel, le traitement de graphes, l’apprentissage machine distribué, le traitement de données textuelles et bien plus encore. Il dispose également de bibliothèques complémentaires telles que Spark SQL, Spark Streaming, MLlib et GraphX, qui étendent encore ses capacités.
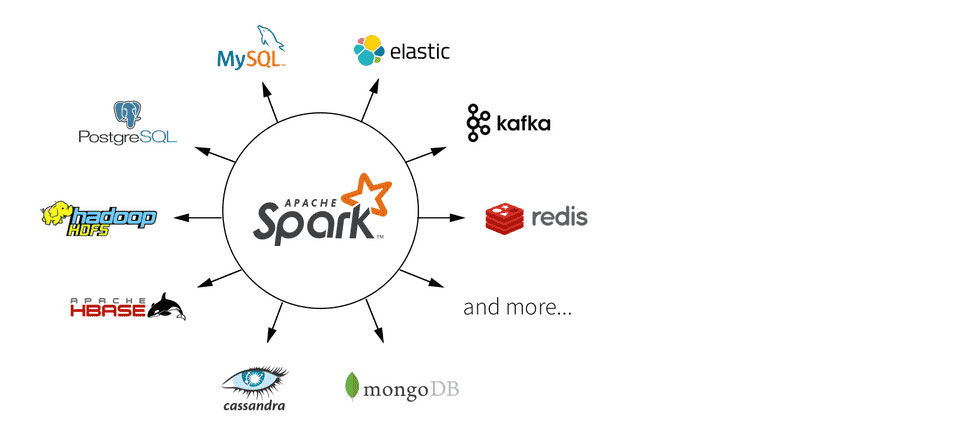
Intégration avec l’écosystème Hadoop : Spark s’intègre facilement avec l’écosystème Hadoop, ce qui permet d’utiliser des outils complémentaires tels que HDFS (Hadoop Distributed File System), Hive, HBase et d’autres. Cela facilite le travail avec des données stockées dans le cadre de l’écosystème Hadoop.
Facilité d’utilisation : Spark est conçu pour être convivial et offre une API simple et intuitive. Les utilisateurs peuvent écrire du code en utilisant des concepts familiers et des opérations de haut niveau, ce qui facilite le développement et la maintenance des applications Spark.
Évolutivité : Spark est conçu pour être hautement évolutif et peut facilement s’adapter à des volumes de données croissants. Il permet de scaler horizontalement en ajoutant simplement de nouveaux nœuds au cluster, ce qui garantit une bonne performance même avec des ensembles de données massifs.
Tout cela fait de Spark un choix populaire pour la data science. En 3 journées, cette formation vous permettra d’adopter Spark pour réaliser vos projets data en toute autonomie.
Spark pour la data science ? Une bonne idée !
Spark est un système de traitement de données open source et distribué, conçu pour fournir une plateforme de calcul rapide et évolutive. Il a été initialement développé à l’Université de Californie à Berkeley et est maintenant maintenu par la fondation Apache. Tout comme Python, Spark est un excellent choix pour faire de la data science :
Vitesse de traitement élevée : Spark est conçu pour le traitement de données en mémoire, ce qui lui permet d’atteindre des performances élevées. Il effectue des opérations de transformation et d’analyse des données de manière très rapide, ce qui permet de réduire considérablement les temps de calcul par rapport à d’autres systèmes.
Capacité de traitement distribué : Spark utilise un modèle de traitement distribué, ce qui signifie qu’il peut répartir les tâches sur plusieurs nœuds d’un cluster. Cela permet de traiter de grands ensembles de données en parallèle, ce qui améliore les performances et permet de faire face à des charges de travail importantes.
Support de plusieurs langages : Spark offre des API dans plusieurs langages de programmation, notamment Scala, Python, Java et R. Cela permet aux utilisateurs de choisir le langage avec lequel ils sont le plus à l’aise et facilite l’intégration de Spark dans leurs workflows existants.
Richesse des fonctionnalités : Spark offre une large gamme de fonctionnalités pour le traitement et l’analyse des données. Il prend en charge le traitement de flux de données en temps réel, le traitement de graphes, l’apprentissage machine distribué, le traitement de données textuelles et bien plus encore. Il dispose également de bibliothèques complémentaires telles que Spark SQL, Spark Streaming, MLlib et GraphX, qui étendent encore ses capacités.
Intégration avec l’écosystème Hadoop : Spark s’intègre facilement avec l’écosystème Hadoop, ce qui permet d’utiliser des outils complémentaires tels que HDFS (Hadoop Distributed File System), Hive, HBase et d’autres. Cela facilite le travail avec des données stockées dans le cadre de l’écosystème Hadoop.
Facilité d’utilisation : Spark est conçu pour être convivial et offre une API simple et intuitive. Les utilisateurs peuvent écrire du code en utilisant des concepts familiers et des opérations de haut niveau, ce qui facilite le développement et la maintenance des applications Spark.
Évolutivité : Spark est conçu pour être hautement évolutif et peut facilement s’adapter à des volumes de données croissants. Il permet de scaler horizontalement en ajoutant simplement de nouveaux nœuds au cluster, ce qui garantit une bonne performance même avec des ensembles de données massifs.
Tout cela fait de Spark un choix populaire pour la data science. En 3 journées, cette formation vous permettra d’adopter Spark pour réaliser vos projets data en toute autonomie.

